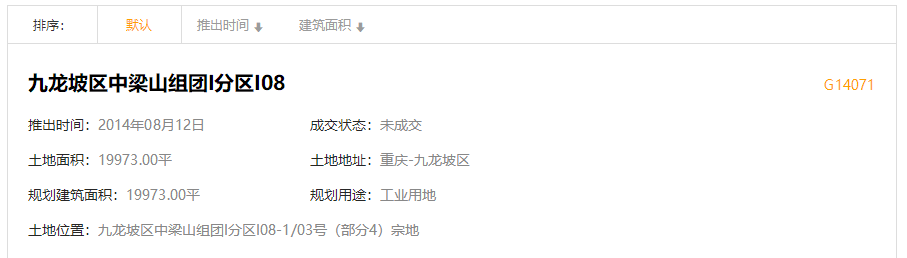
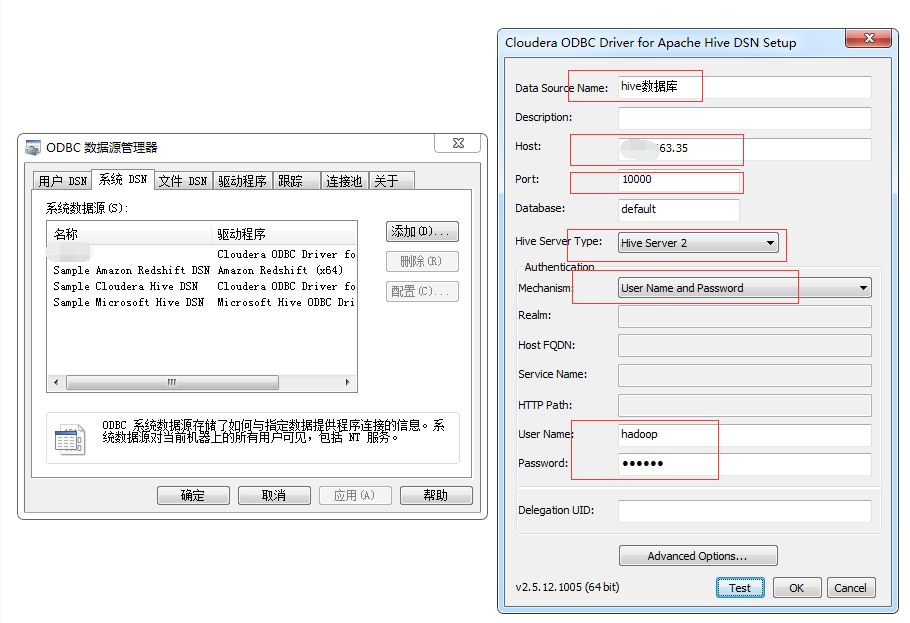
# 见证奇迹的时刻,把电话号码翻译过来
phone="".join([code_dict[p] for p in code_list])
In [18]: phone
Out[18]: '15631267771'
所有代码如下:
code_list='򈊷򈊻򈊼򈊹򈊷򈊸򈊼򈊽򈊽򈊽򈊷'
# 替换&#为0,用于后面直接转换为10进制数
code_list=code_list.replace("&#","0")
# 转换成列表
code_list=code_list.split(';')
# 确定第一个号码1对应的10进制值
c1=int(code_list[0],base=16)
# 创建0-9对应的10进制值
int_list=range(c1-1,c1+9)
# 将其转换为hex
hex_list=[str(hex(i)) for i in int_list]
# 创建0-9的数字对应列表
str_list=[str(i) for i in range(0,10)]
# 组装成字典方便对应
code_dict=dict(zip(hex_list,str_list))
# 见证奇迹的时刻,把电话号码翻译过来
phone="".join([code_dict[p] for p in code_list])
scrapy startproject cq_land
PS C:\WINDOWS\system32> e:
PS E:\> cd E:\web_data
PS E:\web_data> scrapy startproject cq_land
New Scrapy project 'cq_land', using template directory 'c:\\programdata\\anaconda3\\lib\\site-packages\\scrapy\\templates\\project', created in:
E:\web_data\cq_land
You can start your first spider with:
cd cq_land
scrapy genspider example example.com
PS E:\web_data>
class CqLandItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 出让地标题
list_time = scrapy.Field() # 推出时间
# 生成1000以内的汉字和数字对应表
def chnum_to_num(output=0):
ch_num=['零','一','二','三','四','五','六','七','八','九']
for hundred in range(10):
# 如果百位是0,则百位为空,否则返回百位数
if hundred==0:
hundred_ch=""
else:
hundred_ch=ch_num[hundred]+"百"
# 循环十位
for ten in range(10):
# 如果百位和十位都是0,则直接跳过,列表中已包含数据
if hundred==0 and ten==0:
continue
# 百位为0,十位为1的情况
elif hundred==0 and ten==1:
ten_ch='十'
# 百位为不为零,十位为零的情况
elif ten==0:
ten_ch="零"
else:
ten_ch=ch_num[ten]+"十"
# 循环个位
for one in range(10):
# 整百的情况
if hundred>0 and ten==0 and one==0:
ch_num.append("".join([hundred_ch]))
# 个位是0
elif one==0:
ch_num.append("".join([hundred_ch,ten_ch]))
else:
one_ch=ch_num[one]
ch_num.append("".join([hundred_ch,ten_ch,one_ch]))
num=list(range(0,1000))
num_dict=dict(zip(ch_num,num))
# 添加“两”
num_dict['两']=2
# 使用joblib存储文件
if output==0:
joblib.dump(num_dict,path+'templet/chnum_to_num.pkl')
else:
return num_dict
# 处理梯户比(将梯户数转化为梯户比数据)
def lift_proecess(self,data):
num_dict=joblib.load(path+'templet/chnum_to_num.pkl')
# 获取梯和户的汉字
data['ti_ch']=data['lift_family'].map(lambda x: re.findall('(.*)梯',x)[0] if len(re.findall('(.*)梯',x))>0 else None)
data['hu_ch']=data['lift_family'].map(lambda x: re.findall('梯(.*)户',x)[0] if len(re.findall('梯(.*)户',x))>0 else None)
data['ti']=data['ti_ch'].map(lambda x: num_dict[x] if x is not None else None)
data['hu']=data['hu_ch'].map(lambda x: num_dict[x] if x is not None else None)
data['tihu_rate']=data['ti']/data['hu']
# 填充缺失值为0
data['tihu_rate'].fillna(0,inplace=True)
# 删除多余字段
data.drop(['lift_family','hu_ch','ti_ch','ti','hu'],axis=1,inplace=True)
return data
# onehot处理
def onehot(self,data):
data.drop(['building'],axis=1,inplace=True)
var_list=['district','sub_district','room_type','house_stru','fixture','build_stru','property_year','lift','house_type']
# 填充缺失值为“miss”,作为单独一类
for var in var_list:
data[var].fillna('miss',inplace=True)
# 如果是训练数据,则先要讲所有onehot的字典存储下来(存储后再调用来进行onehot编码),如果不是则直接调用训练时所存储的数据进行编码
if self.method=='train':
for var in var_list:
var_values=list(set(data[var]))
joblib.dump(var_values,path+'templet/{}.pkl'.format(var))
# 另一种方法,le_class.classes_
# le_class = preprocessing.LabelEncoder()
# le_class.fit(data[var])
# 读取每一个编码,进行onehot处理
for var in var_list:
print(" ...进行onehot编码,当前变量:{}".format(var))
var_values=joblib.load(path+'templet/{}.pkl'.format(var))
var_cols=[var+"_"+str(j) for j in range(len(var_values))]
# 生成样本量*变量值数量的全0矩阵
temp_data=pd.DataFrame(data=np.zeros((len(data),len(var_values))),columns=var_cols)
# 完成onehot处理,在合适的位置填充1
for i in temp_data.index:
temp_data.iloc[i,var_values.index(data[var][i])]=1
# 将完成了onehot编码的数据合并到DATA中
data=pd.merge(data,temp_data,left_index=True,right_index=True)
# 删除已经完成了onehot编码的数据
data.drop(['district','sub_district','room_type','house_stru','fixture','build_stru','property_year','lift','house_type'],axis=1,inplace=True)
return data
#示例数据集
df=pd.DataFrame(np.arange(12).reshape(4,3),columns=list('abc'),index=list('defg'))
df
Out[189]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
#直接索引行
df.loc['d']
Out[190]:
a 0
b 1
c 2
Name: d, dtype: int32
#索引多行
df.loc[['d','e']]
Out[191]:
a b c
d 0 1 2
e 3 4 5
#索引多列
df.loc[:,:'b']
Out[193]:
a b
d 0 1
e 3 4
f 6 7
g 9 10
#如果索引的标签不在index或columns范围则会报错,a标签在列中,loc的第一个参数为行索引。
df.loc['a']
Traceback (most recent call last):
……
KeyError: 'the label [a] is not in the [index]'
df
Out[196]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
#选取一行
df.iloc[0]
Out[197]:
a 0
b 1
c 2
Name: d, dtype: int32
#选取多行
df.iloc[0:2]
Out[198]:
a b c
d 0 1 2
e 3 4 5
#选取一列或多列
df.iloc[:,2:3]
Out[199]:
c
d 2
e 5
f 8
g 11
df
Out[200]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
#选取一行
df.ix[1]
Out[201]:
a 3
b 4
c 5
Name: e, dtype: int32
#错误的混合索引(想选取第一行和e行)
df.ix[[0,'e']]
Out[202]:
a b c
0 NaN NaN NaN
e 3.0 4.0 5.0
#选取区域(e行的前两列)
df.ix['e':,:2]
Out[203]:
a b
e 3 4
f 6 7
g 9 10
4、at/iat:通过标签或行号获取某个数值的具体位置。
df
Out[204]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
#获取第2行,第3列位置的数据
df.iat[1,2]
Out[205]: 5
#获取f行,a列位置的数据
df.at['f','a']
Out[206]: 6
5、直接索引 df[]
df
Out[208]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
#选取行
df[0:3]
Out[209]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
#选取列
df['a']
Out[210]:
d 0
e 3
f 6
g 9
Name: a, dtype: int32
#选取多列
df[['a','c']]
Out[211]:
a c
d 0 2
e 3 5
f 6 8
g 9 11
#行号和区间索引只能用于行(预想选取C列的数据,
#但这里选取除了df的所有数据,区间索引只能用于行,
#因defg均>c,所以所有行均被选取出来)
df['c':]
Out[212]:
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
df['f':]
Out[213]:
a b c
f 6 7 8
g 9 10 11
#df.选取列
df.a
Out[214]:
d 0
e 3
f 6
g 9
Name: a, dtype: int32
#不能使用df.选择行
df.f
Traceback (most recent call last):
File "<ipython-input-215-6438703abe20>", line 1, in <module>
df.f
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py", line 2744, in __getattr__
return object.__getattribute__(self, name)
AttributeError: 'DataFrame' object has no attribute 'f'
a='大鼎世纪滨江 | 车位 | 39.09平米 | 东 | 无电梯'
b='恒大城二期 | 2室2厅 | 71.49平米 | 东南 | 精装 | 有电梯'
c='协信彩云湖1号 | 叠拼别墅 | 5室2厅 | 280.49平米 | 南 | 简装 | 无电梯'
d=['大鼎世纪滨江 | 车位 | 39.09平米 | 东 | 无电梯',
'恒大城二期 | 2室2厅 | 71.49平米 | 东南 | 精装 | 有电梯',
'协信彩云湖1号 | 叠拼别墅 | 5室2厅 | 280.49平米 | 南 | 简装 | 无电梯']
#实现代码
tpye="别墅" if "别墅" in a else "车位" if "车位" in a else "高层"
#结果
In [177]: "别墅" if "别墅" in a else "车位" if "车位" in a else "高层"
Out[177]: '车位'
In [178]: "别墅" if "别墅" in b else "车位" if "车位" in b else "高层"
Out[178]: '高层'
In [179]: "别墅" if "别墅" in c else "车位" if "车位" in c else "高层"
Out[179]: '别墅'
#对于列表推导式
In [180]: ["别墅" if "别墅" in x else "车位" if "车位" in x else "高层" for x in d]
Out[180]: ['车位', '高层', '别墅']
#对于列表推导式,筛选只包含某个词的的数据
In [181]: ["别墅" for x in d if "别墅" in x]
Out[181]: ['别墅']