在做项目排班的时候经常会遇到一个问题,就是如何在Excel中标记中国的节假日?
经过在网上找各种API,发现不是要钱就是服务器404,再不然就是没有标记完全(比如只标记了节假日,但调休加班没有)。所以,最后还是背靠度娘,通过度娘提供的数据来自己做一个带中国节假日日历列表。
度娘的接口
可以看到query对应的值就是你要查询的年月对应的日历。这里有个好处就是,返回的数据会包含当年的所有节假日和调休加班日,如下:

image.png
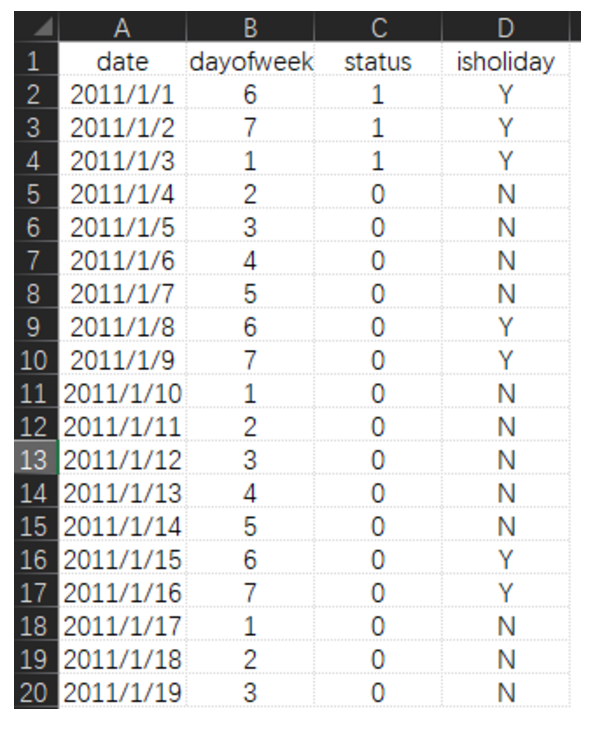
所以,可以在holiday的list中看到当年所有的放假和调休加班(放假对应的status是1,而调休加班则是2),再结合日历本身的周六周日,就可以对当年所有的日期进行标记,最终输出某一天是法定放假还是法定上班了。
以下是,所有代码
以下是对小白的操作
- 用法就是,复制这些文本
- 在本地存储为任意一个text文档
- 将此文档的后缀名由”.txt”修改为”.py”
- 然后使用python运行此文件
- 要修改年份,只需要调整最后的year=2020这个代码就可以了
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 8 17:18:15 2020
@author: 西湖味精三月鲜
"""
# 百度获取日历
# https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=2020%E5%B9%B4&resource_id=6018&format=json
import pandas as pd
import requests
import json
import numpy as np
# 生成某一年的日历
def gen_calendar(year=2020):
# 生成日历列表
start_date=str(year)+'0101'
end_date=str(year)+'1231'
df=pd.DataFrame()
dt=pd.date_range(start_date, end_date,freq='1D')
df['date']=dt
# 计算周几
df['dayofweek']=df['date'].dt.dayofweek+1
# 获取法定节假日
up1='https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='
up2='%E5%B9%B4&resource_id=6018&format=json'
url="".join([up1,str(year),up2])
r=requests.get(url)
r_json=json.loads(r.text)
# 获取放假信息
h_data=r_json['data'][0]['holiday']
h_df=pd.DataFrame()
for i in range(len(h_data)):
each_d=h_data[i]['list']
each_df=pd.DataFrame(each_d)
h_df=h_df.append(each_df)
# 处理一下数据,去重等等
h_df.drop_duplicates(inplace=True)
h_df.reset_index(drop=True,inplace=True)
h_df['date']=pd.to_datetime(h_df['date'])
# 合并数据
df2=pd.merge(df,h_df,how='left',on='date')
df2.fillna(0,inplace=True)
df2['status']=df2['status'].astype('int')
# 返回是否假日
judge=np.where(df2['dayofweek']<6,0,1)+df2['status']
judge=np.where((judge==2) | (judge==1),'Y','N')
df2['isholiday']=judge
return df2
in __name__=="__main__":
year=2020
df=gen_calendar(year)
df2.to_csv('{}年节日历表.csv'.format(year),index=False)
以下是懒人入口,2011-2020年的都在这里
- 只有2011年及之后年份的数据
- 只有国务院公布了放假安排后,才会有当年的数据,比如现在就没有2021年的
- dayofweek是星期几
- status是放假安排的判断,1表示法定放假,2表示法定上班,0没有特殊意义
- isholiday就是最后的结果了,Y表示是法定节假日,N表示是要上班的日子
- 下载链接:
链接:https://pan.baidu.com/s/1M1ehYSAVoLt-WvHlf4EM4Q 提取码:s7wm